E-commerce Text Classification
Product categorization is a type of economic taxonomy that refers to a system of categories into which a collection of products would fall. The problem considered in this project involves the categorization of products offered on e-commerce platforms based on the descriptions of the products mentioned therein. The categories are: Electronics, Household, Books, and Clothing & Accessories. The purpose of such categorization is to enhance the user experience and achieve better results with external search engines.
○ Contents
- Overview
- Introduction
- Exploratory Data Analysis
- Train-Validation-Test Split
- Text Normalization
- TF-IDF Model
- Word2Vec Model
- Prediction and Evaluation
- Acknowledgements
- References
○ Overview
The objective of the project is to classify e-commerce products into four categories, based on its description available in the e-commerce platforms. The categories are:
ElectronicsHouseholdBooksClothing & Accessories
We carried out the following steps in this work:
- We perform exploratory data analysis on the dataset.
- We consider a number of text normalization techniques for product descriptions.
- We use TF-IDF vectorizer on the normalized product descriptions for text vectorization, compared the baseline performance of several classifiers, and perform hyperparameter tuning on the support vector machine classifier with linear kernel. The tuned model obtains a validation accuracy of \(0.952158\).
- In another direction, we employ a few selected text normalization processes on the raw data on product descriptions. Then, we use Google’s pre-trained Word2Vec model on the tokens, obtained from the partially normalized descriptions, to get the embeddings, which are converted to compressed sparse row (CSR) format. The baseline performance of several classifiers are compared. Finally, we perform hyperparameter tuning on the XGBoost classifier. The tuned model obtains a validation accuracy of \(0.948561\).
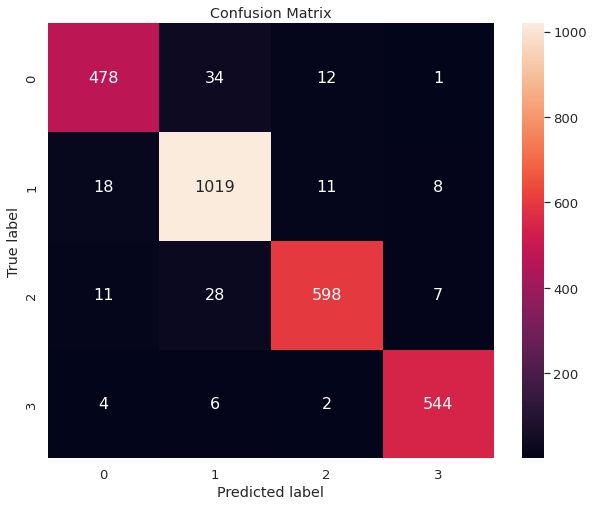
- We employ the tuned model with the highest validation accuracy to predict the labels of the test observations and obtained a test accuracy of \(0.948939\). We present the confusion matrix depicting the test set performance of the model.
○ Introduction
E-commerce Product Categorization
Product categorization or product classification is a type of economic taxonomy that refers to a system of categories into which a collection of products would fall under. Product categorization involves two separate tasks:
- Create, support, and expand the catalogue structure for the offered products.
- Tagging products with the correct categories and attributes.
While machine learning does not have much potential for use in the first task, it is possible to automate the second task, which is relatively laborious and time-consuming.
The problem considered in this project involves the categorization of products offered on e-commerce platforms based on the descriptions of the products mentioned therein.
The purpose of such categorization is to enhance the user experience and achieve better results with external search engines. Visitors can quickly find the products they need by navigating the catalogue or using the website’s search engine.
Text Classification
Text classification is a widely used natural language processing task in different business problems. Given a statement or document, the task involves assigning to it an appropriate category from a pre-defined set of categories. The dataset of choice determines the set of categories. Text classification has applications in emotion classification, news classification, spam email detection, auto-tagging of customer queries etc.
In the present problem, the statements are the product descriptions and the categories are Electronics, Household, Books, and Clothing & Accessories.
Data
Original source: https://doi.org/10.5281/zenodo.3355823
Kaggle dataset: https://www.kaggle.com/datasets/saurabhshahane/ecommerce-text-classification
The dataset has been scraped from Indian e-commerce platform(s). It contains e-commerce text data for four categories: Electronics, Household, Books, and Clothing & Accessories. These four categories cover \(80\%\)
of any e-commerce website, by and large.
The dataset is in .csv format and consists of two columns. The first column gives the target class name and the second column gives the description of the product from the e-commerce website. We insert column names and swap the columns, to put the target column at the right.
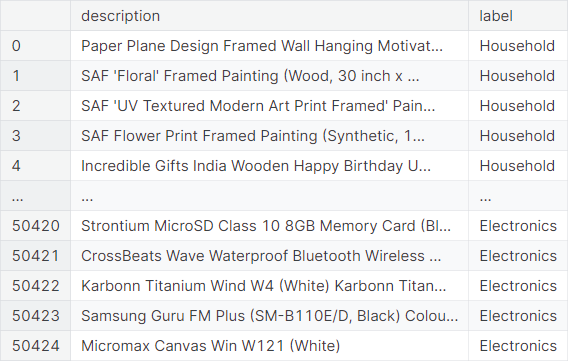
An example description is given as follows.

We observe:
- Total number of observations: \(50425\)
- Number of observations with missing values: \(1\)
- Number of duplicate observations: \(22622\)
We drop the single observation with missing values and drop the duplicate observations.
The labels are manually encoded with the following scheme:

Project Objective
The objective of the project is to classify a product into the four categories Electronics, Household, Books and Clothing & Accessories, based on its description available in the e-commerce platform.
Evaluation Metric
Any prediction about a binary categorical target variable falls into one of the four categories:
- True Positive \(\mapsto\) The classification model correctly predicts the output to be positive
- True Negative \(\mapsto\) The classification model correctly predicts the output to be negative
- False Positive \(\mapsto\) The classification model incorrectly predicts the output to be positive
- False Negative \(\mapsto\) The classification model incorrectly predicts the output to be negative
Let TP, TN, FP and FN respectively denote the number of true positives, true negatives, false positives, and false negatives among the predictions made by a particular classification model.
In this work, we use the accuracy metric to evaluate the models. It is the proportion of correct predictions, given by
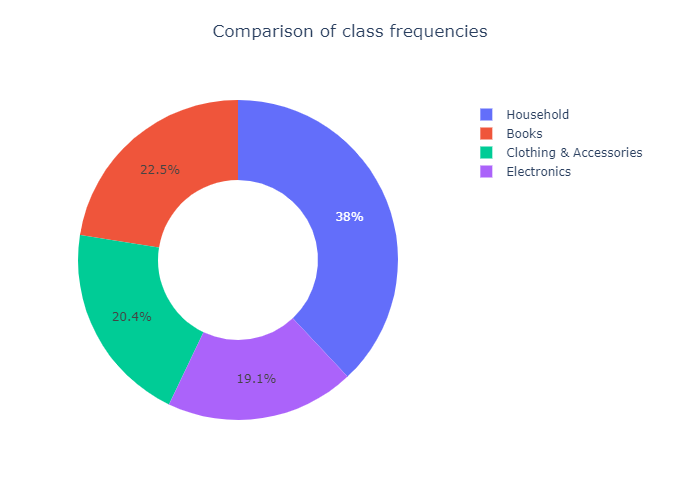
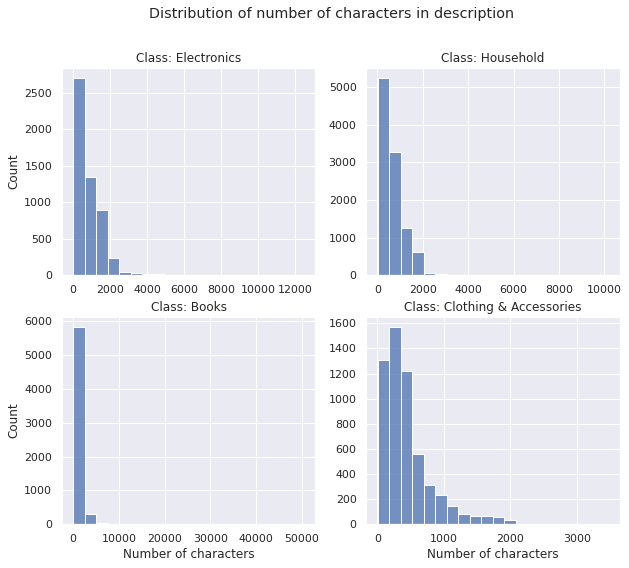
○ Exploratory Data Analysis
Class Frequencies
Number of Characters
Number of Words
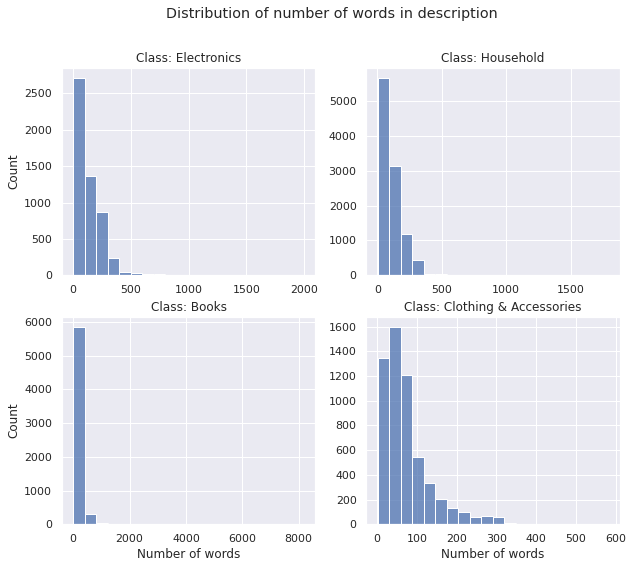
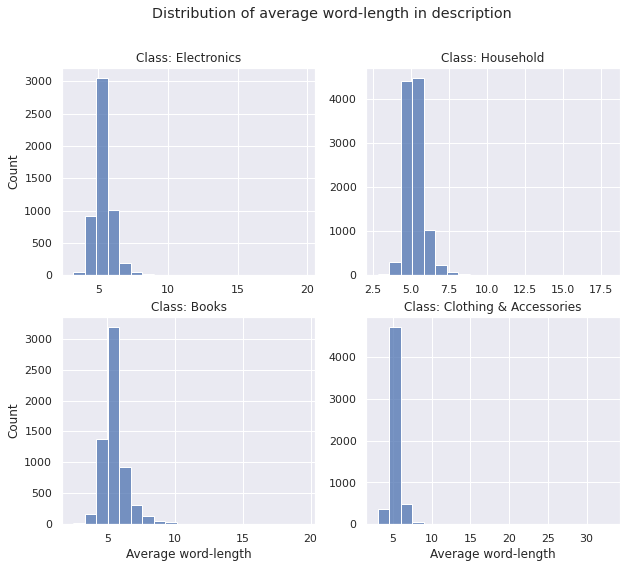
Average Word-length
○ Train-Validation-Test Split
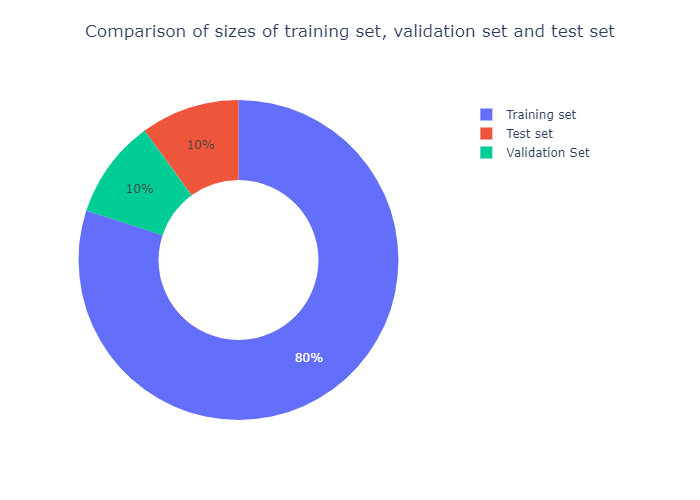
We split the data in \(80 : 10 : 10\) ratio. Specifically, we construct the training set with \(80\%\) observations. The rest of the observations are split into equal halves to form the validation set and the test set.
The sizes of the training set, the validation set, and the test set are compared visually.
○ Text Normalization
- Conversion to Lowercase
- Removal of Whitespaces
- Removal of Punctuations
- Removal of Unicode Characters
- Substitution of Acronyms
- Substitution of Contractions
- Removal of Stop Words
- Spelling Correction
- Stemming and Lemmatization
- Discardment of Non-alphabetic Words
- Retention of Relevant Parts of Speech
- Integration of the Processes
- Implementation on Product Description
Text normalization is the process of transforming text into a single canonical form that it might not have had before. We consider the following text normalization processes.
Conversion to Lowercase
We convert all alphabetical characters of the tweets to lowercase so that the models do not differentiate identical words due to case-sensitivity. For example, without the normalization, Sun and sun would have been treated as two different words, which is not useful in the present context.
def convert_to_lowercase(text):
return text.lower()
Removal of Whitespaces
We remove the unnecessary empty spaces from the tweets.
def remove_whitespace(text):
return text.strip()
Removal of Punctuations
Mostly the punctuations do not play any role in predicting whether a particular tweet indicate disaster or not. Thus we prevent them from contaminating the classification procedures by removing them from the tweets. However, we keep apostrophe since most of the contractions contain this punctuation and will be automatically taken care of once we convert the contractions.
def remove_punctuation(text):
punct_str = string.punctuation
punct_str = punct_str.replace("'", "") # discarding apostrophe from the string to keep the contractions intact
return text.translate(str.maketrans("", "", punct_str))
Removal of Unicode Characters
The training tweets are typically sprinkled with emojis, URLs, and other symbols that do not contribute meaningfully to our analysis, but instead create noise in the learning procedure. Some of these symbols are unique, while the rest usually translate into unicode strings. We remove these irrelevant characters from the data.
First, we remove the HTML tags.
def remove_html(text):
html = re.compile(r'<.*?>')
return html.sub(r'', text)
Next, we remove the emojis.
def remove_emoji(text):
emoji_pattern = re.compile(
"["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE
)
return emoji_pattern.sub(r'', text)
We also remove URLs starting with http.
def remove_http(text):
http = "https?://\S+|www\.\S+" # matching strings beginning with http (but not just "http")
pattern = r"({})".format(http) # creating pattern
return re.sub(pattern, "", text)
Substitution of Acronyms
Acronyms are shortened forms of phrases, generally found in informal writings such as personal messages. Examples:

These time and effort-saving acronyms have received almost universal acceptance in social media platforms including twitter. For the sake of proper modeling, we convert the acronyms, appearing in the tweets, back to their respective original forms. For this purpose, we have compiled an extensive list of English acronyms, which can be found in the file:
english_acronyms_lowercase.json
Note that the file only considers acronyms in lowercase, i.e. it assumes that the textual data have already been transformed to lowercase before substituting the acronyms. For example, the process will convert fyi to for your information but will leave Fyi unchanged.
acronyms_url = 'https://raw.githubusercontent.com/sugatagh/E-commerce-Text-Classification/main/JSON/english_acronyms.json'
acronyms_dict = pd.read_json(acronyms_url, typ = 'series')
acronyms_list = list(acronyms_dict.keys())
The following function converts the acronyms, included in the .json file, appearing in any given input text.
def convert_acronyms(text):
words = []
for word in regexp.tokenize(text):
if word in acronyms_list:
words = words + acronyms_dict[word].split()
else:
words = words + word.split()
text_converted = " ".join(words)
return text_converted
Substitution of Contractions
A contraction is a shortened form of a word or a phrase, obtained by dropping one or more letters. Examples:
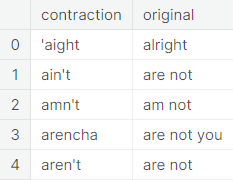
These are commonly used in everyday speech, written dialogue, informal writing and in situations where space is limited or costly, such as advertisements. Usually the missing letters are indicated by an apostrophe, but there are exceptions. We have compiled an extensive list of English contractions, which can be found here:
english_contractions_lowercase.json
Note that the file only considers contractions in lowercase, i.e. it assumes that the textual data have already been transformed to lowercase before substituting the contractions. For example, the process will convert i’ll to i shall but will leave I’ll unchanged.
contractions_url = 'https://raw.githubusercontent.com/sugatagh/E-commerce-Text-Classification/main/JSON/english_contractions.json'
contractions_dict = pd.read_json(contractions_url, typ = 'series')
contractions_list = list(contractions_dict.keys())
The following function converts the contractions, included in the .json file, appearing in any given input text.
def convert_contractions(text):
words = []
for word in regexp.tokenize(text):
if word in contractions_list:
words = words + contractions_dict[word].split()
else:
words = words + word.split()
text_converted = " ".join(words)
return text_converted
Removal of Stop Words
Several words, primarily pronouns, prepositions, modal verbs etc., are identified not to have much effect on the classification procedure. To get rid of the unwanted contamination effect, we remove these words. For this purpose, we use the stopwords module from NLTK. Some of these words are shown below.

stops = stopwords.words("english") # stopwords
addstops = ["among", "onto", "shall", "thrice", "thus", "twice", "unto", "us", "would"] # additional stopwords
allstops = stops + addstops
def remove_stopwords(text):
return " ".join([word for word in regexp.tokenize(text) if word not in allstops])
Spelling Correction
The classification process cannot take misspellings into consideration and treats a word and its misspelt version as separate words. For this reason it is necessary to conduct spelling correction before feeding the data to the classification procedure. We use the pyspellchecker package for this purpose.
The next function corrects the misspelt words in a given input text.
spell = SpellChecker()
def pyspellchecker(text):
word_list = regexp.tokenize(text)
word_list_corrected = []
for word in word_list:
if word in spell.unknown(word_list):
word_corrected = spell.correction(word)
if word_corrected == None:
word_list_corrected.append(word)
else:
word_list_corrected.append(word_corrected)
else:
word_list_corrected.append(word)
text_corrected = " ".join(word_list_corrected)
return text_corrected
Stemming and Lemmatization
Stemming is the process of reducing the words to their root form or stem. It reduces related words to the same stem even if the stem is not a dictionary word. For example, the words introducing, introduced, introduction reduce to a common word introduce. However, the process often produces stems that are not actual words. The sentence Introducing lemmatization as an improvement over stemming becomes introduc lemmat as an improv over stem upon applying the stemming procedure. The stems introduc, lemmat and improv are not actual words. Here we use the Porter stemming algorithm.
The function to implement stemming is as follows.
stemmer = PorterStemmer()
def text_stemmer(text):
text_stem = " ".join([stemmer.stem(word) for word in regexp.tokenize(text)])
return text_stem
Lemmatization offers a more sophisticated approach by utilizing a corpus to match root forms of the words. Unlike stemming, it uses the context in which a word is being used. Upon applying lemmatization, the same sentence becomes introduce lemmatization as an improvement over stem. Here we use the spaCy lemmatizer.
We implement lemmatization through the following function.
spacy_lemmatizer = spacy.load("en_core_web_sm", disable = ['parser', 'ner'])
def text_lemmatizer(text):
text_spacy = " ".join([token.lemma_ for token in spacy_lemmatizer(text)])
return text_spacy
Discardment of Non-alphabetic Words
The non-alphabetic words are not numerous and create unnecessary diversions in the context of classifying tweets into non-disaster and disaster categories. Hence we discard these words.
def discard_non_alpha(text):
word_list_non_alpha = [word for word in regexp.tokenize(text) if word.isalpha()]
text_non_alpha = " ".join(word_list_non_alpha)
return text_non_alpha
Retention of Relevant Parts of Speech
The parts of speech provide a great tool to select a subset of words that are more likely to contribute in the classification procedure and discard the rest to avoid noise. The idea is to select a number of parts of speech that are important to the context of the problem. Then we partition the words in a given text into several subsets corresponding to each part of speech and keep only those subsets corresponding to the selected parts of speech. An alphabetical list of part-of-speech tags used in the Penn Treebank Project is given here.
def keep_pos(text):
tokens = regexp.tokenize(text)
tokens_tagged = nltk.pos_tag(tokens)
keep_tags = ['NN', 'NNS', 'NNP', 'NNPS', 'FW', 'PRP', 'PRPS', 'RB', 'RBR', 'RBS', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WPS', 'WRB']
keep_words = [x[0] for x in tokens_tagged if x[1] in keep_tags]
return " ".join(keep_words)
Integration of the Processes
We integrate the text normalization processes in appropriate order into one single function. Note that the spelling correction step takes a massive amount of time to run on large datasets and hence may be commented out for a quick implementation.
def text_normalizer(text):
text = convert_to_lowercase(text)
text = remove_whitespace(text)
text = re.sub('\n' , '', text) # converting text to one line
text = re.sub('\[.*?\]', '', text) # removing square brackets
text = remove_http(text)
text = remove_punctuation(text)
text = remove_html(text)
text = remove_emoji(text)
text = convert_acronyms(text)
text = convert_contractions(text)
text = remove_stopwords(text)
text = pyspellchecker(text)
text = text_lemmatizer(text) # text = text_stemmer(text)
text = discard_non_alpha(text)
text = keep_pos(text)
text = remove_additional_stopwords(text)
return text
Implementation on Product Description
We perform text normalization on the description column of the training set, the validation set, and the test set. The normalized description and label of the training observations are shown below:

○ TF-IDF Model
In the context of information retrieval, TF-IDF (short for term frequency-inverse document frequency), is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling.
The TF-IDF value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general.
Thus, the measure objectively evaluates how relevant a word is to a text in a collection of texts, taking into consideration that some words appear more frequently in general. For more details, check this note.
Text Vectorization
In order to perform machine learning on text data, we must transform the documents into vector representations. In natural language processing, text vectorization is the process of converting words, sentences, or even larger units of text data to numerical vectors.
We begin by separating the feature variable and the target variable in the training set, the validation set, and the test set.
Next, we use the TfidfVectorizer class to convert the lists of normalized texts to matrices of token counts. We create an instance of this class by setting the ngram_range parameter, with the default choice being \((1, 1).\)
TfidfVec = TfidfVectorizer(ngram_range = (1, 1))
Note: The parameter gives the lower and upper boundary of the range of \(n\)-values
corresponding to different word \(n\)-grams
to be extracted, i.e. all values of \(n\)
such that \(\text{min}_n \leq n \leq \text{max}_n\)
will be used. For example, an ngram_range of \((1, 1)\)
means only words, \((1, 2)\)
means words and bigrams, and \((2, 2)\)
means only bigrams.
Next, we vectorize the lists of normalized product descriptions in the training set, the validation set, and the test set.
X_train_tfidf = TfidfVec.fit_transform(X_train_norm)
X_val_tfidf = TfidfVec.transform(X_val_norm)
X_test_tfidf = TfidfVec.transform(X_test_norm)
TF-IDF Baseline Modeling
We give a summary of the baseline models considered.
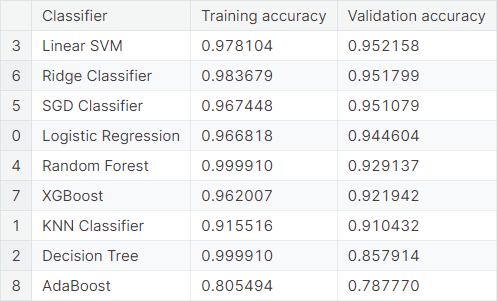
TF-IDF Hyperparameter Tuning
We perform hyperparameter tuning on the best performing baseline model, which is support vector machine classifier with linear kernel. We set the parameter grid used for tuning the hyperparameters.
params_svm = {
'kernel': ['linear'],
'C': [0.1, 1, 10, 100]
}
Next, we perform the tuning operation and report the summary of each gridpoint.
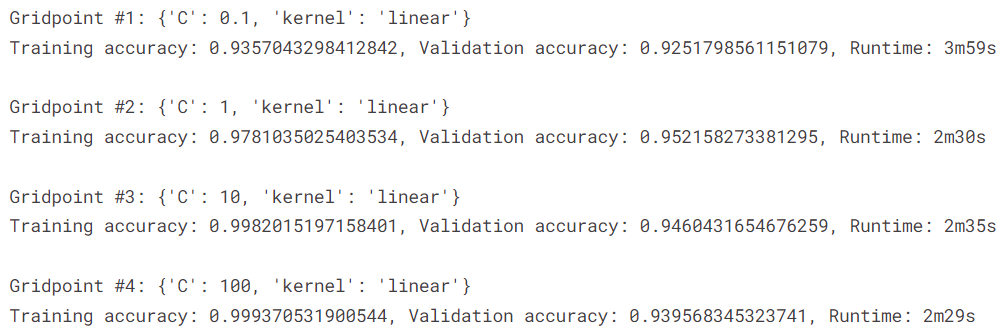
The best model is given below.
best_model_tfidf = SVC(C = 1, kernel = 'linear')
It obtains a validation accuracy of \(0.952158\).
○ Word2Vec Model
In the context of natural language processing, word embeddings are used for representing a word in terms of a real-valued vector that encodes the meaning of the word such that the words that are close in the vector space are expected to be similar in meaning. It can capture the context of a word in a document, as well as identify semantic and syntactic similarity and other contextual relations with other words in the document.
Word2Vec is a specific word-embedding technique that uses a neural network model to learn word associations from a reasonably large corpus of text. After training, the model can detect similar words and recommend words to complete a partial sentence. As its name suggests, word2vec maps each distinct word to a vector, which is assigned in such a way that the level of semantic similarity between words is indicated by a simple mathematical operation on the vectors that the words are mapped to (for instance, the cosine similarity between the vectors).
Partial Text Normalization
Standard text normalization processes like stemming, lemmatization, or removal of stop words are not recommended when we have pre-trained embeddings.
The reason behind this is that valuable information, which could be used by the neural network, is lost by those preprocessing steps.
Here we shall implement a few selected text normalization processes only, before we feed the tokenized words to the pre-trained model to get the embeddings. We give a snapshot of the training set after implementing partial text normalization and tokenization.

Word Embedding
We load the pretrained word2vec model and use it to embed the processed descriptions in the training set, the validation set, and the test set. The embedded observations in the training set, color-coded by their respective label, are visualized below.
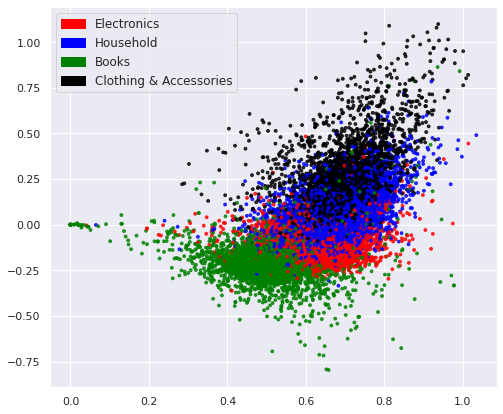
We convert the embeddings to compressed sparse row matrix before feeding them to the algorithms.
Word2Vec Baseline Modeling
We give a summary of baseline models.
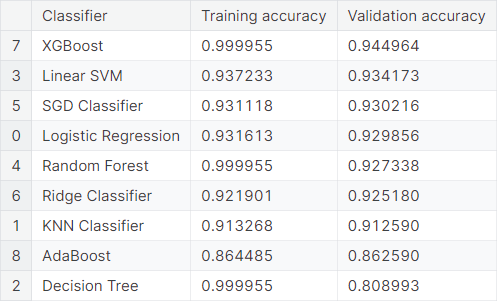
Word2Vec Hyperparameter Tuning
We perform hyperparameter tuning on the best performing baseline model, which is the XGBoost classifier. We set the parameter grid used for tuning the hyperparameters.
params_xgb = {
'learning_rate': [0.03, 0.3],
'min_child_weight': [0, 10],
'n_estimators': [200],
'reg_lambda': [1, 2],
'seed': [40]
}
Next, we perform the tuning operation and report the summary of each gridpoint.

The best model is given below.
best_model_w2v = XGBClassifier(
learning_rate = 0.3,
min_child_weight = 0,
n_estimators = 200,
reg_lambda = 1,
seed = 40
)
It obtains a validation accuracy of \(0.948561\).
○ Prediction and Evaluation
We choose the best model (in terms of validation accuracy) between the tuned models from TF-IDF and Word2Vec approaches.
We fit the chosen model on the training set and use it to predict on the test set. It obtains a test accuracy of \(0.948939\).
The confusion matrix depicting the performance of the best model on the test set is given below.
○ Acknowledgements
- Alphabetical list of part-of-speech tags used in the Penn Treebank Project
- List of English contractions
- A Guide on XGBoost hyperparameters tuning by Prashant Banerjee
- Ecommerce Text Classification dataset
- Gautam. (2019). E commerce text dataset (version - 2) [Data set]. Zenodo.
- Machine Learning in eCommerce Product Categorization by Nikolay Sidelnikov
○ References
- Accuracy
- Canonical form
- Contractions
- Corpus
- E-commerce
- Economic taxonomy
- Exploratory data analysis
- Hyperparameter tuning
- Information retrieval
- Inverse document frequency
- Natural language processing
- Product classification
- SpaCy lemmatizer
- Sparse matrix
- Support vector machine
- Term frequency
- Text mining
- Text normalization
- TF-IDF
- User modeling
- Word embedding
- Word2Vec
- XGBoost